今天要介紹的是優化 mutation 的方法,同時這也是優化 fuzzer 系列的最後一篇文章。Mutation 中文翻譯為變異,也就是對 input 做隨機化的處理,不過即使是隨機化,通常也會制定一系列有意義的隨機操作,並不是完全的 "隨機"。
以 AFL 來說,當對 input 做 mutation 時,會依序進入 deterministic 階段、havoc 階段與 splice 階段,各階段所做的操作如下:
因此實際上這些半隨機的行為是可以被調整的,其中論文 MOpt: Optimized Mutation Scheduling for Fuzzers 將已知的演算法應用在 mutation 做優化,並且由於模型已經透過數學證明有效,所以不用擔心是否單純只是 heuristic。最後測試結果表示,比起一般的 mutation 策略,MOpt 在同樣的時間內找到了更多的 bug。
接下來會從 MOpt 的論文著手,探討研究人員的觀察與發現,以及如何將粒子群最佳化演算法實作在 mutation,有效提升 fuzzing 的能力。
AFL 的 mutation 操作有一定的意義在,因為如果程式沒有特別對整數做檢查,輸入 edge value 確實很容易造成 integer overflow/underflow,導致程式執行不符合預期,但這也產生一個疑問:如果 input 只會被視為純字串,那比起把一些 bytes 替換成 edge value,反而增加字串長度會比較有可能戳到漏洞,像是 buffer overflow?更精確來說,是否每個程式都有比較適合的 mutation 操作?
研究人員提出了這個疑問,並且實際做了一些測試,而實驗結果也證明了這個猜想是正確的,對於不同的程式,有些 input 做 bitflip 就會產生比較多 path,有些反而是 arith 操作比較有效。以此為基礎,如果 fuzzer 能夠自動找到適合的 mutation 操作,或許就能有效提升 coverage,要做到這件事情也很直觀:
不過 MOpt 的實作方式又更聰明一些,他將 mutation 的操作對應到粒子群最佳化演算法,也就是 Particle Swarm Optimization (PSO),讓 fuzzer 能找到當前較為適合的 mutation 策略。接下來會介紹 PSO 以及 MOpt 是如何將 fuzzing 的機制對應到演算法的變數。
PSO 是一個能在沒有太多資訊的情況下,有效找到局部最佳解的演算法,而下方會根據維基百科定義,為 PSO 演算法做詳細的介紹。
將每個個體看作是 D 維搜尋空間中的一個沒有體積的微粒 (點),這群微粒在第 d+1 維 (1 ≤ d+1 ≤ D) 的變化為方程式 1:
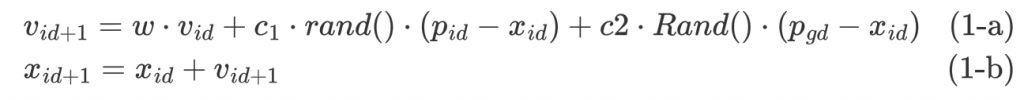
標準的 PSO 執行流程如下:
簡單來說,每個微粒個體的位置會不斷做更新,而每次更新會建立在慣性、常數與隨機性,並且數學式參考了局部最佳與歷史最佳位置,讓微粒群同時具備全域搜尋與局部搜尋能力。
MOpt 將 fuzzing 使用到的機制與 PSO 做對應,將 MOPT 的微粒對應到 mutation 操作,而這些微粒試圖在事先定義好的機率空間探索最佳位置,也就是產生最多 interesting test 的地方,x 則代表著 mutation 操作被選到的機率。兩者名詞對照如下:
而其他常數就根據使用者需求給予初始值,不過因為被挑選的機率總和應該要是 1,因此 MOpt 有對更新結果做標準化。
MOpt 也額外定義名詞 efficiency,定義為 "找到的 interesting test" 除以 "更新時該 mutation 操作做了幾次",efficiency 也分成 local、global 以及 now,分別為局部最佳、全域最佳以及當前的 eifficiency。我自己將 efficiency 定義成 "interesting test 數量" 除以 "機率",其實就是斜率 (y/x)。
為了避免特定操作進到局部最佳解,因此 MOpt 還使用多個微粒群做計算,並且讓微粒的更新直接參考所有微粒群中的最佳位置。
最後 fuzzer 會選擇最好的 swarm 做為各個 mutation 操作的機率,後續在 fuzzing 時就能使用優化過的 mutation 策略。
這個做法聽起來就很有用,先測量每個 mutation 操作的好壞,之後 fuzzing 時就傾向使用較好的 mutation 操作,降低不必要或沒什麼用的 mutation 的執行機率,況且 MOpt 使用的 PSO 演算法還有用數學證明過有效。我看過不少直接將數學模型或演算法引入 fuzzer 的論文,而且都是發在不錯的會議,或許對 mutation 優化有興趣的讀者,可以找找有哪些模型或演算法可以對應上去,如果實驗結果很好,就可以投稿看看了。
這幾天介紹了 fuzzer 的優化,加上先前文章的介紹,讀者應該已經對於 userspace fuzzing 有非常深入的理解,剩下的幾天會介紹 OS fuzzer 與 hypervisor fuzzer,前者會介紹 kAFL 與 syzkaller 的實作機制,其中 syzkaller 已經成為 OS fuzzer 的翹楚;後者會介紹 nyx,如果還有時間也會介紹 hyperCube。

